


Groups of up to 25,000 starlings have been seen flying in abstract, yet highly organised formation. If you’ve witnessed a starling murmuration, you might recall that the flock – almost swarm-like – appears not to have a central leader, yet each bird knows precisely what direction to take at any given moment to enable the flock to move in perfect synchronicity.
But this is not just a pretty stunt; rather, it is an illustration of how optimal outcomes can be produced when intelligence is aggregated and utilised at a group level, an emerging concept known as swarm intelligence.
Swarm learning conceptually
Swarm intelligence is the theory underpinning swarm learning, a machine learning technique premised on information sharing across a secure, decentralised, and privacy-preserving network to enable intelligence to develop at a group level.
Put simply, individual systems upload insights and learnings they produce to a common network, which incrementally refines a core model that all participants have the benefit of using: i.e. the data is locally stored and only the insights are shared and used centrally.
How it works
- An entity (for example, a data analytics company) applies to be a participant to the swarm network, which takes place over blockchain technology.
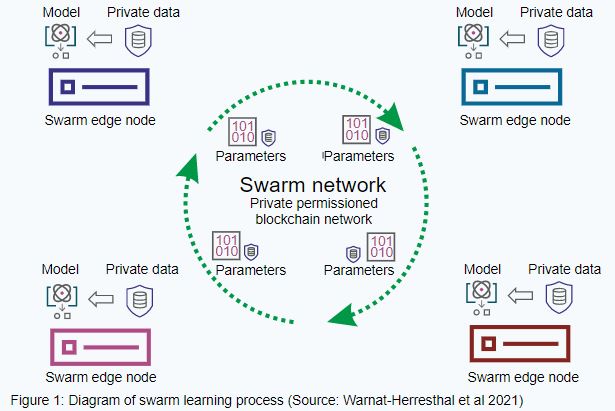
- Once the entity is authorised, it enters into a blockchain smart contract and sits at the swarm edge node.
- Within the swarm network, the entity obtains the core model. It undertakes local training on the core model, using private data until certain modelling conditions are met and model parameters are generated.
- Model parameters are then exchanged between participants via a swarm application programming interface.The parameters are merged, which modifies the core model at the group level with the updated parameter settings.
- A new round of model ‘training’ takes place, continuously updating the model and making it more capable of producing optimal results.
Why use swarm learning?
Swarm learning is set apart from other machine learning models in three distinct ways:
- Data efficiency: In centralised machine learning models, private data and parameters are uploaded to a central custodian. In federated machine learning models, only the parameters are uploaded to a central custodian. These models can give rise to data duplication and traffic. Conversely, in local learning AI models, the lack of sharing amongst entities means datasets are usually too small to trust the AI learning. The emphasis on group-level intelligence and the decentralised nature of swarm learning prevents such data inefficiencies.
- Data sovereignty: only the de-identified learnings are loaded to the swarm network. This means the raw data (which often contains private and identifiable information) remains with the data owner, ultimately giving the individual who provided the data more direct transparency and control over the data and its uses. This resolves issues of ownership and privacy, which may arise if data and parameters were simply loaded to a central custodian (like a cloud server) for everyone to use, as would occur in centralised or federated machine learning models.
- Data security: the permissioned characteristic of the blockchain technology underpinning swarm learning ensures that only defined participants can contribute to the swarm network. Moreover, by design, blockchain technology enhances transparency in transactions and can prevent attacks on the core model.
Case study: medical applications
Sharing large pools of medical and health data about individuals undoubtedly improves diagnoses, refine treatment options, reduce resource burdens, and aid in drug development. Ultimately, information sharing can produce optimal medical outcomes for the patient.
Yet, global privacy laws largely prohibit medical entities from engaging in critical information sharing. The fate of My Health Record shows that promoting the health benefits of ‘big data’ will not overcome deep-seated consumer (or patient) resistance and suspicion. Medical researchers, developers, and providers are restricted to using locally developed models, producing inconsistent, duplicated, and unoptimised results.
In 2021, a study demonstrated that swarm learning can produce outcomes superior to those produced by local, centralised and federated learning models.
Using a swarm network, the study took distributed data and developed disease classifiers to identify particular diseases in patients. For example, developed a swarm network and core model to identify COVID-19 in patients using diverse data from European medical entities. When comparing the swarm learning results with the results from local learning models, the study found that swarm learning outperformed the local learning results in identifying COVID-19. The study undertook a similar process for predicting leukemias and, again, found that swarm learning outperformed the local learning results and was either close to or equivalent to the results produced by a centralised learning model.
Most critically, the study demonstrated how swarm learning can simultaneously:
- Enhance medical outcomes through group-level learning
- Enable widespread information sharing in a manner that is compliant with global privacy laws
Swarm learning has real potential to accelerate the progression of precise medicine and drug development, enhance the quality of research, and ensure consistent and accurate medical diagnoses. Combined, these outcomes ultimately facilitate optimal patient outcomes.
Where to from here
The concept of swarm learning is gaining traction worldwide in a range of industries. In addition to the medical application, the theoretical underpinning of swarm learning was tested in the context of transportation engineering and in the Internet of Vehicles.
The EU is ‘operationalising’ its privacy regulation, the GDPR, in the AI context by investing in the Gaia-X Project, which is pioneering the practical application of swarm learning usage across Europe. With over 300 participating companies and government bodies spanning the commerce, science and politics sectors, Gaia-X is developing a decentralised and secure data-sharing network. An early identified application of Gaia-X is to enable banks to identify credit fraud based on fraud profile-based data shared across Europe on a privacy-preserving swarm learning network.
One swarm does not a summer make
While the benefits of an effective swarm learning network are overwhelming, there are challenges that remain unaddressed.
Debate ensues about the scope for regulating blockchain: how do we protect the blockchain from exploitation that ultimately harms consumers while ensuring it operates free from restrictive government interference? This challenge arises in the context of swarm learning: regulation of the swarm learning blockchain undermines its decentralised and peer-to-peer quality, which could reduce user trust in the system. Entities will not share their learnings or insights to a network that they do not trust. With limited users, the breadth of knowledge in the network is limited, which reduces the optimality of the results produced by the core model.
Further, despite the decentralised and ‘leaderless’ nature of swarm learning, it remains unclear who sets the criteria for joining the swarm network. What happens to unauthorised entities that are effectively excluded from the benefits of aggregated knowledge? Could such exclusion even constitute anticompetitive or collusive conduct?
While interesting regulatory questions remain unresolved, there is no doubt that swarm learning pushes the boundaries of innovation and the possibility of information-sharing in a world increasingly concerned with privacy preservation.